Коэффициент корреляции используется в том случае, когда нужно определить значение зависимости между значениями. Позже эти данные задают в одной таблице которая определяется как матрица корреляции. С помощью программы Microsoft Excel можно сделать расчёт корреляции.
Коэффициент корреляции определяется некоторыми данными. Если уровень показателя составляет от 0 до 0.3, то в таком случае связи нет. Если показатель составляет от 0.3 до 0.5 - это слабая связь. Если показатель доходит до 0.7, то связь средняя. Высокой можно назвать когда показатель достигает отметки 0.7-0.9. Если показатель составляет 1 - это наиболее сильная связь.
Первым делом нужно подключить пакет анализа данных. Без его активации дальнейшие действия нельзя провести. Подключить его можно открыв раздел "Главная" и в меню выбрать "Параметры".
Далее откроется новое окно. В нём нужно выбрать "Надстройки" и в поле управления параметрами выбрать среди элементов списка "Надстройки Excel"
После запуска окна параметров посредством его левого вертикального меню переходим в раздел «Надстройки». После этого нажимаем "Перейти".


После этих действий можно начать работу. Создана таблица с данными и на её примере сделаем нахождение множественного коэффициента корреляции.
Для начала откроем раздел "Данные" и среди инструментария выбираем "Анализ данных".

Откроется специальное окно с инструментами для анализа. Выбираем "Корреляция" и подтверждаем действие.

Перед пользователем появится новое окно с параметрами. Как входной интервал задается диапазон значений в таблице. Задать можно как в ручную так и выделив данные, которые будут отображены в специальном поле. Также можно разгруппировать элементы таблицы. Вывод сделаем на текущей странице, а значит в настройках параметра вывода выбираем "Выходной интервал". После этого подтверждаем действие.
1.Открыть программу Excel
2.Создать столбцы с данными. В нашем примере мы будем считать взаимосвязь, или корреляцию, между агрессивностью и неуверенностью в себе у детей-первоклассников. В эксперименте участвовали 30 детей, данные представлены в таблице эксель:
1 столбик — № испытуемого
2 столбик — агрессивность в баллах
3 столбик — неуверенность в себе в баллах
3.Затем необходимо выбрать пустую ячейку рядом с таблицей и нажать на значок f(x) в панели Excel

4.Откроется меню функций, среди категорий необходимо выбрать Статистические , а затем среди списка функций по алфавиту найти КОРРЕЛ и нажать ОК

5.Затем откроется меню аргументов функции, которое позволит выбрать нужные нам столбики с данными. Для выбора первого столбика Агрессивность нужно нажать на синюю кнопочку у строки Массив1

6.Выберем данные для Массива1 из столбика Агрессивность и нажмем на синюю кнопочку в диалоговом окне

7. Затем аналогично Массиву 1 нажмём на синюю кнопочку у строки Массив2

8.Выберем данные для Массива2 — столбик Неуверенность в себе и опять нажмем синюю кнопку, затем ОК

9.Вот, коэффициент корреляции r-Пирсона посчитан и записан в выбранной ячейке.В нашем случае он положительный и приблизительно равен 0,225 . Это говорит об умеренной положительной связи между агрессивностью и неуверенностью в себе у детей-первоклассников

Таким образом, статистическим выводом эксперимента будет: r = 0,225, выявлена умеренная положительная взаимосвязь между переменными агрессивность и неуверенность в себе.
В некоторых исследованиях требуется указывать р-уровень значимости коэффициента корреляции, однако программа Excel, в отличие от SPSS, не предоставляет такой возможности. Ничего страшного, есть (А.Д. Наследов).
Также Вы можете и приложить её к результатам исследования.

Вычислим коэффициент корреляции и ковариацию для разных типов взаимосвязей случайных величин.
Коэффициент корреляции (критерий корреляции Пирсона, англ. Pearson Product Moment correlation coefficient) определяет степень линейной взаимосвязи между случайными величинами.
Как следует из определения, для вычисления коэффициента корреляции требуется знать распределение случайных величин Х и Y. Если распределения неизвестны, то для оценки коэффициента корреляции используется выборочный коэффициент корреляции r (еще он обозначается как R xy или r xy ) :

где S x – стандартное отклонение выборки случайной величины х, вычисляемое по формуле:

Как видно из формулы для расчета корреляции , знаменатель (произведение стандартных отклонений) просто нормирует числитель таким образом, что корреляция оказывается безразмерным числом от -1 до 1. Корреляция и ковариация предоставляют одну и туже информацию (если известны стандартные отклонения ), но корреляцией удобнее пользоваться, т.к. она является безразмерной величиной.
Рассчитать коэффициент корреляции и ковариацию выборки в MS EXCEL не представляет труда, так как для этого имеются специальные функции КОРРЕЛ() и КОВАР() . Гораздо сложнее разобраться, как интерпретировать полученные значения, большая часть статьи посвящена именно этому.
Теоретическое отступление
Напомним, что корреляционной связью называют статистическую связь, состоящую в том, что различным значениям одной переменной соответствуют различные средние значения другой (с изменением значения Х среднее значение Y изменяется закономерным образом). Предполагается, что обе переменные Х и Y являются случайными величинами и имеют некий случайный разброс относительно их среднего значения .
Примечание . Если случайную природу имеет только одна переменная, например, Y, а значения другой являются детерминированными (задаваемыми исследователем), то можно говорить только о регрессии.
Таким образом, например, при исследовании зависимости среднегодовой температуры нельзя говорить о корреляции температуры и года наблюдения и, соответственно, применять показатели корреляции с соответствующей их интерпретацией.
Корреляционная связь между переменными может возникнуть несколькими путями:
- Наличие причинной зависимости между переменными. Например, количество инвестиций в научные исследования (переменная Х) и количество полученных патентов (Y). Первая переменная выступает как независимая переменная (фактор) , вторая - зависимая переменная (результат) . Необходимо помнить, что зависимость величин обуславливает наличие корреляционной связи между ними, но не наоборот.
- Наличие сопряженности (общей причины). Например, с ростом организации растет фонд оплаты труда (ФОТ) и затраты на аренду помещений. Очевидно, что неправильно предполагать, что аренда помещений зависит от ФОТ. Обе этих переменных во многих случаях линейно зависят от количества персонала.
- Взаимовлияние переменных (при изменении одной, вторая переменная изменяется, и наоборот). При таком подходе допустимы две постановки задачи; любая переменная может выступать как в роли независимой переменной и в роли зависимой.
Таким образом, показатель корреляции показывает, насколько сильна линейная взаимосвязь между двумя факторами (если она есть), а регрессия позволяет прогнозировать один фактор на основе другого.
Корреляция , как и любой другой статистический показатель, при правильном применении может быть полезной, но она также имеет и ограничения по использованию. Если показывает четко выраженную линейную зависимость или полное отсутствие взаимосвязи, то корреляция замечательно это отразит. Но, если данные показывают нелинейную взаимосвязь (например, квадратичную), наличие отдельных групп значений или выбросов, то вычисленное значение коэффициента корреляции может ввести в заблуждение (см. файл примера ).
Корреляция близкая к 1 или -1 (т.е. близкая по модулю к 1) показывает сильную линейную взаимосвязь переменных, значение близкое к 0 показывает отсутствие взаимосвязи. Положительная корреляция означает, что с ростом одного показателя другой в среднем увеличивается, а при отрицательной – уменьшается.
Для вычисления коэффициента корреляции требуется, чтобы сопоставляемые переменные удовлетворяли следующим условиям:
- количество переменных должно быть равно двум;
- переменные должны быть количественными (например, частота, вес, цена). Вычисленное среднее значение этих переменных имеет понятный смысл: средняя цена или средний вес пациента. В отличие от количественных, качественные (номинальные) переменные принимают значения лишь из конечного набора категорий (например, пол или группа крови). Этим значениям условно сопоставлены числовые значения (например, женский пол – 1, а мужской – 2). Понятно, что в этом случае вычисление среднего значения , которое требуется для нахождения корреляции , некорректно, а значит некорректно и вычисление самой корреляции ;
- переменные должны быть случайными величинами и иметь .
Двумерные данные могут иметь различную структуру. Для работы с некоторыми из них требуются определенные подходы:
- Для данных с нелинейной связью корреляцию нужно использовать с осторожностью. Для некоторых задач бывает полезно преобразовать одну или обе переменных так, чтобы получить линейную взаимосвязь (для этого требуется сделать предположение о виде нелинейной связи, чтобы предложить нужный тип преобразования).
- С помощью диаграммы рассеяния у некоторых данных можно наблюдать неравную вариацию (разброс). Проблема неодинаковой вариации состоит в том, что места с высокой вариацией не только предоставляют наименее точную информацию, но и оказывают наибольшее влияние при расчете статистических показателей. Эту проблему также часто решают с помощью преобразования данных, например, с помощью логарифмирования.
- У некоторых данных можно наблюдать разделение на группы (clustering), что может свидетельствовать о необходимости разделения совокупности на части.
- Выброс (резко отклоняющееся значение) может исказить вычисленное значение коэффициента корреляции. Выброс может быть причиной случайности, ошибки при сборе данных или могут действительно отражать некую особенность взаимосвязи. Так как выброс сильно отклоняется от среднего значения, то он вносит большой вклад при расчете показателя. Часто расчет статистических показателей производят с и без учета выбросов.
Использование MS EXCEL для расчета корреляции
В качестве примера возьмем 2 переменные Х и Y и, соответственно, выборку состоящую из нескольких пар значений (Х i ; Y i). Для наглядности построим .
Примечание : Подробнее о построении диаграмм см. статью . В файле примера для построения диаграммы рассеяния использована , т.к. мы здесь отступили от требования случайности переменной Х (это упрощает генерацию различных типов взаимосвязей: построение трендов и заданный разброс). В случае реальных данных необходимо использовать диаграмму типа Точечная (см. ниже).
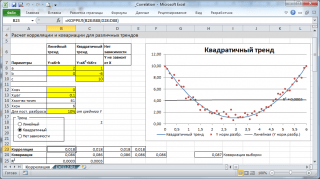
Расчеты корреляции проведем для различных случаев взаимосвязи между переменными: линейной, квадратичной и при отсутствии связи .
Примечание : В файле примера можно задать параметры линейного тренда (наклон, пересечение с осью Y) и степень разброса относительно этой линии тренда. Также можно настроить параметры квадратичной зависимости.
В файле примера для построения диаграммы рассеяния в случае отсутствия зависимости переменных использована диаграмма типа Точечная. В этом случае точки на диаграмме располагаются в виде облака.

Примечание : Обратите внимание, что изменяя масштаб диаграммы по вертикальной или горизонтальной оси, облаку точек можно придать вид вертикальной или горизонтальной линии. Понятно, что при этом переменные останутся независимыми.
Как было сказано выше, для расчета коэффициента корреляции в MS EXCEL существует функций КОРРЕЛ() . Также можно воспользоваться аналогичной функцией PEARSON() , которая возвращает тот же результат.
Для того, чтобы удостовериться, что вычисления корреляции производятся функцией КОРРЕЛ() по вышеуказанным формулам, в файле примера приведено вычисление корреляции с помощью более подробных формул:
=КОВАРИАЦИЯ.Г(B28:B88;D28:D88)/СТАНДОТКЛОН.Г(B28:B88)/СТАНДОТКЛОН.Г(D28:D88)
=КОВАРИАЦИЯ.В(B28:B88;D28:D88)/СТАНДОТКЛОН.В(B28:B88)/СТАНДОТКЛОН.В(D28:D88)
Примечание : Квадрат коэффициента корреляции r равен коэффициенту детерминации R2, который вычисляется при построении линии регрессии с помощью функции КВПИРСОН() . Значение R2 также можно вывести на диаграмме рассеяния , построив линейный тренд с помощью стандартного функционала MS EXCEL (выделите диаграмму, выберите вкладку Макет , затем в группе Анализ нажмите кнопку Линия тренда и выберите Линейное приближение ). Подробнее о построении линии тренда см., например, в .

Использование MS EXCEL для расчета ковариации
Ковариация близка по смыслу с (также является мерой разброса) с тем отличием, что она определена для 2-х переменных, а дисперсия - для одной. Поэтому, cov(x;x)=VAR(x).

Для вычисления ковариации в MS EXCEL (начиная с версии 2010 года) используются функции КОВАРИАЦИЯ.Г() и КОВАРИАЦИЯ.В() . В первом случае формула для вычисления аналогична вышеуказанной (окончание .Г обозначает Генеральная совокупность ), во втором – вместо множителя 1/n используется 1/(n-1), т.е. окончание .В обозначает Выборка .
Примечание : Функция КОВАР() , которая присутствует в MS EXCEL более ранних версий, аналогична функции КОВАРИАЦИЯ.Г() .
Примечание : Функции КОРРЕЛ() и КОВАР() в английской версии представлены как CORREL и COVAR. Функции КОВАРИАЦИЯ.Г() и КОВАРИАЦИЯ.В() как COVARIANCE.P и COVARIANCE.S.
Дополнительные формулы для расчета ковариации :
=СУММПРОИЗВ(B28:B88-СРЗНАЧ(B28:B88);(D28:D88-СРЗНАЧ(D28:D88)))/СЧЁТ(D28:D88)
=СУММПРОИЗВ(B28:B88-СРЗНАЧ(B28:B88);(D28:D88))/СЧЁТ(D28:D88)
=СУММПРОИЗВ(B28:B88;D28:D88)/СЧЁТ(D28:D88)-СРЗНАЧ(B28:B88)*СРЗНАЧ(D28:D88)
Эти формулы используют свойство ковариации :

Если переменные x и y независимые, то их ковариация равна 0. Если переменные не являются независимыми, то дисперсия их суммы равна:
VAR(x+y)= VAR(x)+ VAR(y)+2COV(x;y)
А дисперсия их разности равна
VAR(x-y)= VAR(x)+ VAR(y)-2COV(x;y)
Оценка статистической значимости коэффициента корреляции
Для того чтобы проверить гипотезу, мы должны знать распределение случайной величины, т.е. коэффициента корреляции r. Обычно, проверку гипотезы осуществляют не для r, а для случайной величины t r:

которая имеет с n-2 степенями свободы.
Если вычисленное значение случайной величины |t r | больше, чем критическое значение t α,n-2 (α- заданный ), то нулевую гипотезу отклоняют (взаимосвязь величин является статистически значимой).

Надстройка Пакет анализа
В для вычисления ковариации и корреляции имеются одноименные инструменты анализа .

После вызова инструмента появляется диалоговое окно, которое содержит следующие поля:

- Входной интервал : нужно ввести ссылку на диапазон с исходными данными для 2-х переменных
- Группирование : как правило, исходные данные вводятся в 2 столбца
- Метки в первой строке : если установлена галочка, то Входной интервал должен содержать заголовки столбцов. Рекомендуется устанавливать галочку, чтобы результат работы Надстройки содержал информативные столбцы
- Выходной интервал : диапазон ячеек, куда будут помещены результаты вычислений. Достаточно указать левую верхнюю ячейку этого диапазона.
Надстройка возвращает вычисленные значения корреляции и ковариации (для ковариации также вычисляются дисперсии обоих случайных величин).

Вы уже сталкивались с необходимостью рассчитать степень связи двух статистических величин и определить формулу, по которой они коррелируют? Нормальный человек может спросить, зачем это вообще может быть нужно. Как ни странно, это действительно бывает нужно. Знание достоверных корреляций может помочь вам зарабатывать бешенные деньги, если вы, скажем, биржевой трейдер. Проблема в том, что почему-то эти корреляции никто не раскрывает (удивительно, не правда ли?).
Давайте посчитаем их сами! Для примера, я решил попробовать посчитать корреляцию рубля к доллару через евро. Давайте разберем, как это делается подробно.
Эта статья рассчитана на продвинутый уровень владения Microsoft Excel. Если у вас нет времени читать всю статью, вы можете скачать файл и разобраться с ним самостоятельно.
Если вы часто сталкиваетесь с необходимостью сделать что-то подобное , настоятельно рекомендую подумать о покупке книги Статистические вычисления в среде Excel .
Что важно знать о корреляциях
Чтобы рассчитать достоверную корреляцию, необходимо иметь достоверную выборку, чем больше она будет, тем достовернее будет результат. Для целей данного примера я взял ежедневную выборку курсов валют за 10 лет. Данные есть в свободном доступе, я их брал с сайта http://oanda.com .
Что я, собственно, сделал
(1) Когда у меня были исходные данные, я начал с того, что проверил степень корреляции этих двух наборов данных. Для этого я воспользовался функцией CORREL (КОРРЕЛ) - о ней есть немного информации . Она возвращает степень корреляции двух диапазонов данных. Результат, прямо скажем, получился не особенно впечатляющим (всего около 70%). А вообще говоря, степень соотношения двух величин принято считать, как квадрат этой величины, то есть корреляция получилась достоверной приблизительно на 49%. Это очень мало!
(2) Мне это показалось очень странным. Какие ошибки могли закрасться в мои расчеты? Поэтому я решил построить график и посмотреть, что могло произойти. График был простоен специально с разбивкой по годам, чтобы можно было визуально увидеть, где рвет корреляцию. График получился вот таким

(3) Из графика очевидно, что на диапазоне около 35 рублей за евро корреляцию начинает рвать на две части. Из-за этого она и получилась недостоверной. Необходимо было определить в связи с чем это происходит.
(4) По цвету видно, что эти данные относятся к 2007, 2008, 2009 годам. Конечно! Периоды экономических пиков и спадов обычно недостоверны статистически, что и произошло в данном случае. Поэтому я попробовал исключить из данных эти периоды (ну и для проверки, я проверрил степень корреляции данных в этом периоде). Степень корреляции только этих данных составляет 0.01%, то есть она отсутствует в принципе. Зато без них данные коррелируют приблизительно на 81%. Это уже достаточно достоверная корреляция. Вот график с функцией.

Дальнейшие шаги
Теоретически, функцию корреляции можно уточнить, если перевести ее из линейной в экспоненциальную или логарифмическую. При этом статистическая достоверность корреляции вырастает приблизительно на один процент, но сложность применения формулы повышается неимоверно. Поэтому для себя я ставлю вопрос: а нужно ли это на самом деле? Решать вам - для каждого конкретного случая.
Где x·y , x , y - средние значения выборок; σ(x), σ(y) - среднеквадратические отклонения.
Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b: , где σ(x)=S(x), σ(y)=S(y) - среднеквадратические отклонения, b - коэффициент перед x в уравнении регрессии y=a+bx .
Другие варианты формул:
или 
К xy - корреляционный момент (коэффициент ковариации)
![]()

Линейный коэффициент корреляции принимает значения от –1 до +1 (см. шкалу Чеддока). Например, при анализе тесноты линейной корреляционной связи между двумя переменными получен коэффициент парной линейной корреляции, равный –1 . Это означает, что между переменными существует точная обратная линейная зависимость.
Геометрический смысл коэффициента корреляции : r xy показывает, насколько различается наклон двух линий регрессии: y(x) и х(у) , насколько сильно различаются результаты минимизации отклонений по x и по y . Чем больше угол между линиями, то тем больше r xy .Знак коэффициента корреляции совпадает со знаком коэффициента регрессии и определяет наклон линии регрессии, т.е. общую направленность зависимости (возрастание или убывание). Абсолютная величина коэффициента корреляции определяется степенью близости точек к линии регрессии.
Свойства коэффициента корреляции
- |r xy | ≤ 1;
- если X и Y независимы, то r xy =0, обратное не всегда верно;
- если |r xy |=1, то Y=aX+b, |r xy (X,aX+b)|=1, где a и b постоянные, а ≠ 0;
- |r xy (X,Y)|=|r xy (a 1 X+b 1 , a 2 X+b 2)|, где a 1 , a 2 , b 1 , b 2 – постоянные.
Инструкция . Укажите количество исходных данных. Полученное решение сохраняется в файле Word (см. Пример нахождения уравнения регрессии). Также автоматически создается шаблон решения в Excel . .



